In R, you can use the %in% operator to check if a value (or values) belong to a vector.
a %in% b
The above reads “a exists in b”. The result is a boolean value or a list of booleans.
This is a comprehensive guide to using the %in% operator in R.
Because checking the existence of values is a useful thing to do, there are countless use cases for the %in% operator in R. This guide teaches you 7 notable use cases for the %in% operator. Besides, you will learn what’s the difference between the == operator and the %in% operator.
What Does %in% Mean in R?
The %in% operator checks if an element (or elements) are present in a vector or data frame.
For example, you can use the %in% operator to check if number 1 is part of a sequence of numbers 1,2,3,4,5:
1 %in% c(1,2,3,4,5) # [1] TRUE
You can also use the %in% operator on two lists. When used this way, the operator checks if the individual elements in the first list exist in the second one. In this case, the result is a list of boolean values.
c(1,5,7) %in% c(1,2,3,4,5) # [1] TRUE TRUE FALSE
The best way to learn how to use the %in% operator is by seeing some examples. The following section shows you 7 common use cases for the %in% operators.
7 Use Cases for the %in% Operator in R
This section teaches you 7 common use cases for the %in% operator. At the end of this section, you’ll also find a bonus use case for the %in% operator, so make sure to read all the way to the end!
1. Check the Existence of Numbers in Sequences

A common way to use the %in% operator in R is to check if the values in one sequence exist in another.
For example, let’s check which numbers in the sequence 1, 2, 3, 4, 5 are present in a sequence of 3, 4, 5, 6, 7, 8, 9, 10.
a <- seq(1, 5) b <- seq(3, 10) a %in% b
Output:
[1] FALSE FALSE TRUE TRUE TRUE
Here’s an illustration of how the above comparison is made:
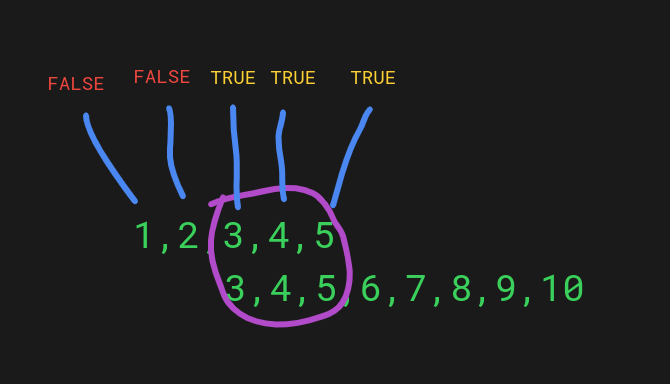
As you can tell from the image, the %in% operator performs a check on each value of the first list to see if it exists in the second list. If a value exists, the operation returns TRUE. If the value doesn’t exist, the operation returns FALSE in the resulting list.
Speaking of checking which values exist in sequences, you can use the which() function to return the indices of the numbers that exist in another sequence.
For example:
a <- seq(1, 5) b <- seq(3, 10) which(a %in% b)
Output:
[1] 3 4 5
This is useful to see the indices of the values instead of booleans indicating the existence.
Speaking of sequences, make sure to read my complete guide to using the seq() function in R.
2. Check the Existence of Vectors Elements

This use case is similar to the previously mentioned number sequence one. You can use the %in% operator to check the existence of vector elements in another vector.
For example, let’s check what letters of a vector are found in another:
a <- LETTERS[1:5] b <- LETTERS[3:8] a %in% b
Output:
[1] FALSE FALSE TRUE TRUE TRUE
Let’s take a look at another example of vectors and the %in% operator. Also, let’s return the indices of the vector elements that exist in the other vector instead of boolean values:
a <- c("A", "B", "C")
b <- c("X", "A", "Y", "B")
which(a %in% b)
Output:
[1] 1 2
Because only the first and second letters (“A” and “B”) are found in vector b, indices 1 and 2 are returned.
3. Add a New Column to Dataframe
Let’s take a look at an example. First, let’s build a data frame that represents the products of a store:
shopping_list = data.frame(PRODUCT_GROUP = c("Fruit","Fruit","Fruit","Fruit","Fruit","Vegetable","Vegetable","Vegetable","Vegetable","Dairy","Dairy"),
PRODUCT_NAME = c("Banana","Apple","Mango","Orange","Papaya","Carrot","Potato","Cucumber","Tomato","Milk","Yogurt"),
Price = c(1,0.8,0.7,0.9,0.7,0.6,0.8,0.75,0.15,0.3,1.1),
Tax = c(NA,NA,24,3,20,30,NA,10,NA,12,15))
shopping_list
Here’s what the data frame looks like:
PRODUCT_GROUP PRODUCT_NAME Price Tax 1 Fruit Banana 1.00 NA 2 Fruit Apple 0.80 NA 3 Fruit Mango 0.70 24 4 Fruit Orange 0.90 20 5 Fruit Papaya 0.70 20 6 Vegetable Carrot 0.60 30 7 Vegetable Potato 0.80 NA 8 Vegetable Cucumber 0.75 10 9 Vegetable Tomato 0.15 NA 10 Dairy Milk 1.10 12 11 Dairy Yogurt 1.10 15
Now, let’s use the %in% operator for adding a new column to the table of products called IS_VEGETABLE. The value is YES if the product is “Vegetable” in PRODUCT_GROUP and NO if it’s not:
# Add an IS_VEGETABLE column with values based on PRODUCT_GROUP
shopping_list=within(shopping_list,{
IS_VEGETABLE='NO'
IS_VEGETABLE[PRODUCT_GROUP %in% c("Vegetable")]='YES'
IS_VEGETABLE[PRODUCT_GROUP %in% c("Fruit","Dairy")]='NO'
})
shopping_list
Output:
PRODUCT_GROUP PRODUCT_NAME Price Tax IS_VEGETABLE 1 Fruit Banana 1.00 NA NO 2 Fruit Apple 0.80 NA NO 3 Fruit Mango 0.70 24 NO 4 Fruit Orange 0.90 20 NO 5 Fruit Papaya 0.70 20 NO 6 Vegetable Carrot 0.60 30 YES 7 Vegetable Potato 0.80 NA YES 8 Vegetable Cucumber 0.75 10 YES 9 Vegetable Tomato 0.15 NA YES 10 Dairy Milk 1.10 12 NO 11 Dairy Yogurt 1.10 15 NO
Now there’s a new column called IS_VEGETABLE. The %in% operator helped to set the values NO/YES based on the PRODUCT_GROUP.
- IS_VEGETABLE[PRODUCT_GROUP %in% c(“Vegetable”)]=’YES’ checks if the product group of the current product exists in the list “Vegetable”.
- IS_VEGETABLE[PRODUCT_GROUP %in% c(“Fruit”,”Dairy”)]=’NO’ checks if the product group exists in the list “Fruit”, “Dairy”.
4. Remove a Column from a Dataframe

Another way you can use the %in% operator in R is to help remove a particular column from a data frame.
The best way to demonstrate this is by taking a look at an example.
Let’s construct the product table you saw earlier:
shopping_list = data.frame(PRODUCT_GROUP = c("Fruit","Fruit","Fruit","Fruit","Fruit","Vegetable","Vegetable","Vegetable","Vegetable","Dairy","Dairy"),
PRODUCT_NAME = c("Banana","Apple","Mango","Orange","Papaya","Carrot","Potato","Cucumber","Tomato","Milk","Yogurt"),
Price = c(1,0.8,0.7,0.9,0.7,0.6,0.8,0.75,0.15,0.3,1.1),
Tax = c(NA,NA,24,3,20,30,NA,10,NA,12,15))
shopping_list
Here’s what the table looks like:
PRODUCT_GROUP PRODUCT_NAME Price Tax 1 Fruit Banana 1.00 NA 2 Fruit Apple 0.80 NA 3 Fruit Mango 0.70 24 4 Fruit Orange 0.90 20 5 Fruit Papaya 0.70 20 6 Vegetable Carrot 0.60 30 7 Vegetable Potato 0.80 NA 8 Vegetable Cucumber 0.75 10 9 Vegetable Tomato 0.15 NA 10 Dairy Milk 1.10 12 11 Dairy Yogurt 1.10 15
Now, let’s remove the Tax column of the table:
shopping_list[, !(colnames(shopping_list) %in% c("Tax"))]
Output:
PRODUCT_GROUP PRODUCT_NAME Price 1 Fruit Banana 1.00 2 Fruit Apple 0.80 3 Fruit Mango 0.70 4 Fruit Orange 0.90 5 Fruit Papaya 0.70 6 Vegetable Carrot 0.60 7 Vegetable Potato 0.80 8 Vegetable Cucumber 0.75 9 Vegetable Tomato 0.15 10 Dairy Milk 1.10 11 Dairy Yogurt 1.10
Now the Tax column no longer exists.
Let’s take a quick look at the expression !(colnames(shopping_list) %in% c(“Tax”)). This expression removes all the columns whose name doesn’t belong to the group “Tax”.
Notice that there are cleaner ways for removing a single column. But if you’re removing multiple columns, then using the %in% operator makes more sense.
5. Select Columns

One useful way to use the %in% operator is when choosing particular columns of a data frame using the dplyr library’s select_if function. Similar to the previous use cases, you can use the %in% operator to select only those columns whose names belong to a group of values.
Make sure to have the dplyr package installed to make the examples work.
Let’s take a look at an example.
Once again, let’s construct the shopping_list table that represents the products of a store:
shopping_list = data.frame(PRODUCT_GROUP = c("Fruit","Fruit","Fruit","Fruit","Fruit","Vegetable","Vegetable","Vegetable","Vegetable","Dairy","Dairy"),
PRODUCT_NAME = c("Banana","Apple","Mango","Orange","Papaya","Carrot","Potato","Cucumber","Tomato","Milk","Yogurt"),
Price = c(1,0.8,0.7,0.9,0.7,0.6,0.8,0.75,0.15,0.3,1.1),
Tax = c(NA,NA,24,3,20,30,NA,10,NA,12,15))
shopping_list
Here’s what the data frame looks like:
PRODUCT_GROUP PRODUCT_NAME Price Tax 1 Fruit Banana 1.00 NA 2 Fruit Apple 0.80 NA 3 Fruit Mango 0.70 24 4 Fruit Orange 0.90 20 5 Fruit Papaya 0.70 20 6 Vegetable Carrot 0.60 30 7 Vegetable Potato 0.80 NA 8 Vegetable Cucumber 0.75 10 9 Vegetable Tomato 0.15 NA 10 Dairy Milk 1.10 12 11 Dairy Yogurt 1.10 15
Now, let’s select some specific columns from the table. For example, let’s pick the columns “PRODUCT_NAME” and “Price“:
library(dplyr)
shopping_list %>%
select_if(names(.) %in% c('PRODUCT_NAME', 'Price'))
Output:
PRODUCT_NAME Price 1 Banana 1.00 2 Apple 0.80 3 Mango 0.70 4 Orange 0.90 5 Papaya 0.70 6 Carrot 0.60 7 Potato 0.80 8 Cucumber 0.75 9 Tomato 0.15 10 Milk 1.10 11 Yogurt 1.10
The idea in the above code is similar to the previous examples in the previous sections. Use the %in% operator to check if the column names belong to a group. Then only choose the columns whose name belongs to the group.
6. Check If a Value Is in Column

You’ve learned you can use the %in% operator in R to check if a value or group of values belongs to a group of values.
This gives raise to yet another useful use case for the %in% operator: Check if a value exists in a column.
Similar to the previous examples, let’s first construct the shopping_list data frame that represents the products of a store:
shopping_list = data.frame(PRODUCT_GROUP = c("Fruit","Fruit","Fruit","Fruit","Fruit","Vegetable","Vegetable","Vegetable","Vegetable","Dairy","Dairy"),
PRODUCT_NAME = c("Banana","Apple","Mango","Orange","Papaya","Carrot","Potato","Cucumber","Tomato","Milk","Yogurt"),
Price = c(1,0.8,0.7,0.9,0.7,0.6,0.8,0.75,0.15,0.3,1.1),
Tax = c(NA,NA,24,3,20,30,NA,10,NA,12,15))
shopping_list
Here’s the original table of products that the above code creates:
PRODUCT_GROUP PRODUCT_NAME Price Tax 1 Fruit Banana 1.00 NA 2 Fruit Apple 0.80 NA 3 Fruit Mango 0.70 24 4 Fruit Orange 0.90 20 5 Fruit Papaya 0.70 20 6 Vegetable Carrot 0.60 30 7 Vegetable Potato 0.80 NA 8 Vegetable Cucumber 0.75 10 9 Vegetable Tomato 0.15 NA 10 Dairy Milk 1.10 12 11 Dairy Yogurt 1.10 15
Now, let’s check if a product with the name “Banana” exists in the PRODUCT_NAME column:
"Banana" %in% shopping_list$PRODUCT_NAME
Output:
[1] TRUE
The above code is easy to understand. shopping_list$PRODUCT_NAME returns a list of all the product names in the data frame. Then the %in% operator checks if “Banana” exists in that list.
Make sure to read also my complete guide to the $ operator in R.
7. Filter Data

Last but not least, let’s have a look at filtering data with the %in% operator.
In dplyr library, there’s a function filter you can use to filter data of a data frame. When you call the filter function, it only returns particular rows of the table.
This example uses the dplyr package. Make sure to have it installed to repeat the code examples.
The best way to demonstrate the %in% operator in filtering is by taking a look at an example.
Let’s construct the shopping_list table once more:
shopping_list = data.frame(PRODUCT_GROUP = c("Fruit","Fruit","Fruit","Fruit","Fruit","Vegetable","Vegetable","Vegetable","Vegetable","Dairy","Dairy"),
PRODUCT_NAME = c("Banana","Apple","Mango","Orange","Papaya","Carrot","Potato","Cucumber","Tomato","Milk","Yogurt"),
Price = c(1,0.8,0.7,0.9,0.7,0.6,0.8,0.75,0.15,0.3,1.1),
Tax = c(NA,NA,24,3,20,30,NA,10,NA,12,15))
shopping_list
Here’s what the table looks like:
PRODUCT_GROUP PRODUCT_NAME Price Tax 1 Fruit Banana 1.00 NA 2 Fruit Apple 0.80 NA 3 Fruit Mango 0.70 24 4 Fruit Orange 0.90 20 5 Fruit Papaya 0.70 20 6 Vegetable Carrot 0.60 30 7 Vegetable Potato 0.80 NA 8 Vegetable Cucumber 0.75 10 9 Vegetable Tomato 0.15 NA 10 Dairy Milk 1.10 12 11 Dairy Yogurt 1.10 15
Now, let’s filter the table so that only the “Carrot”, “Tomato”, and “Banana” rows are left:
library(dplyr)
selected_products <- c("Carrot", "Tomato", "Banana")
# Subsetting using %in% in R:
shopping_list %>%
filter(PRODUCT_NAME %in% selected_products)
Output:
PRODUCT_GROUP PRODUCT_NAME Price Tax 1 Fruit Banana 1.00 NA 2 Vegetable Carrot 0.60 30 3 Vegetable Tomato 0.15 NA
In the above code, the filter() function checks that the product name is either “Carrot“, “Tomato“, or “Banana“. Otherwise, it leaves the product out of the result.
Bonus Tip: Create a %notin% Operator

As a bonus use case for the %in% operator, you can create a negated %in% operator and call it %notin%.
All you need to do is run this piece of code:
`%notin%` <- Negate(`%in%`)
Now you can call the %notin% operator anywhere in the code to check if a value or group of values is not present in another group of values.
For example, let’s check if the value 9 is not in a group of numbers 1, 2, and 3:
a = c(1, 2, 3) b = 9 b %notin% a
Output:
[1] TRUE
%in% vs == in R
In R, the operators %in% and == might seem similar. In some use cases, the result might even be the same. But the meaning of these operators is completely different.
- %in% is a value-matching operation. You can use it to check if elements of a vector match at least one element in another vector.
- == is a logical comparison operator that checks if two values are exactly equal to one another in vectors of values. (If the vector lengths don’t match, they will be recycled).
Here’s an example that demonstrates the difference between == and %in% operators:
# 1. The == operator 1:4 == rep(1:3, 2) # [1] TRUE TRUE TRUE FALSE FALSE FALSE # 2. The %in% operator 1:4 %in% rep(1:3, 2) # [1] TRUE TRUE TRUE FALSE
The first example checks if the group 1,2,3,4 equals to 1,2,3,1,2,3. Because only the first three values of group 1,2,3,1,2,3 are present in group 1,2,3,4, the result is TRUE TRUE TRUE FALSE FALSE FALSE.
The second example separately checks if each individual number in 1,2,3,4 exist in group 1,2,3,1,2,3. Because the numbers 1, 2, and 3 all exist but the number 4 doesn’t, the result is TRUE, TRUE, TRUE, FALSE.
Summary
Today you learned what is the %in% operator in R. More importantly, you learned how to use it in your programs.
To recap, the %in% operator checks if a value is present in a list of values.
a %in% b
This reads “a exists in b”.
You can call the %in% operator on two lists or sequences as well. In this case, the %in% operator checks if each value in the first list is present in the second one.
Checking the presence of a value (or values) is useful when filtering, adding, removing, and selecting columns or rows in a data frame.
Thanks for reading. Happy coding!